Kollaboratives Filtern
Beim kollaborativen Filtern (collaborative filtering) werden Verhaltensmuster von Benutzergruppen ausgewertet, um auf die Interessen Einzelner zu schließen. Dabei handelt es sich um eine Form des Data-Mining, die eine explizite Nutzereingabe überflüssig macht.
Ziel
BearbeitenDie Anwendung von kollaborativem Filtern erfolgt meistens für sehr große Datenmengen. Kollaboratives Filtern wird für die verschiedensten Bereiche angewandt wie z. B. im Finanzdienstleistungssektor zur Integration finanzieller Quellen oder in Anwendungen im eCommerce und Web 2.0. Dieser Artikel beschäftigt sich mit dem kollaborativen Filtern für Benutzerdaten, auch wenn manche Methoden und Ansätze auf andere Bereiche übertragen werden können.
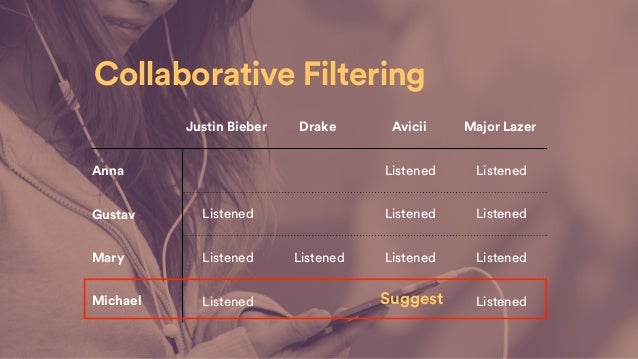
Das Ziel der Methode ist eine automatische Vorhersage (Filtern) von Benutzerinteressen. Zu diesem Zweck werden Informationen über das Verhalten und Vorlieben von möglichst vielen Nutzern gesammelt. Die zugrunde liegende Annahme von kollaborativem Filtern ist, dass wenn zwei Personen dieselben Vorlieben zu ähnlichen Produkten haben, sie sich auch in anderen Produkten einig sind. Daher auch der Begriff Kollaboration: Möchte man wissen, welche Meinung ein Nutzer A zu einem Artikel hat, betrachtet man welche Meinung andere Nutzer zu diesem Artikel haben. Wobei man nur Nutzer betrachtet deren Meinung bei möglichst vielen Artikeln mit der Meinung von Nutzer A übereinstimmt. Die anderen Nutzer arbeiten zusammen um die Frage zu lösen welcher Meinung wohl Nutzer A ist.
Durch kollaboratives Filtern kann z. B. für ein Fernsehprogramm eine Vorhersage gemacht werden, welche Fernsehsendung einem Zuschauer gefallen könnte. Dabei betrachtet man die Fernsehgewohnheiten des Zuschauers und vergleicht sie mit den Gewohnheiten anderer Zuschauer. Die Zuschauer deren Gewohnheiten am ähnlichsten zu denen des betrachteten Zuschauers sind, werden nun für die Empfehlung neuer Sendungen herangezogen. Der Output wäre eine Liste mit möglichen favorisierten Fernsehsendungen. Es gilt zu beachten, dass diese Vorhersage für jeden einzelnen Zuschauer individuell gemacht wird. Die Datengrundlage zur Vorhersage wird von der Gesamtheit der Nutzer gesammelt. Hier unterscheidet sich das kollaborative Filtern von einfacheren Methoden, bei denen ein unspezifischer Mittelwert errechnet wird.
Ein spezifisches Problem kollaborativer Filter besteht in ihrer Latenzzeit: Ein neuer Nutzer tritt mit einem leeren Benutzerprofil in das System ein. Da seine Interessen noch nicht bekannt sind, kann er zu Beginn keine sinnvollen Empfehlungen erhalten. Gleiches gilt für neu in das System eintretende Elemente (z. B. Produkte in einem Online-Shop). Sie weisen keine quantifizierbare Ähnlichkeit mit anderen Elementen auf und können damit nicht sinnvoll empfohlen werden. Es handelt sich bei kollaborativen Filtern also um lernende Systeme und damit um eine Form der künstlichen Intelligenz.
Methodik
BearbeitenKollaboratives Filtern läuft meistens in zwei Schritten ab.
- Suche nach Nutzern, die das gleiche Verhaltensmuster wie der aktive Nutzer haben. (= der Nutzer für den die Vorhersage getroffen wird)
- Verwendung der Verhaltensmuster um eine Vorhersage für den aktiven Nutzer zu treffen.
Alternativ dazu gibt es das artikelbasierte kollaborative Filtern, das durch Amazon.com bekannt wurde („Das könnte Sie auch interessieren.“) und erstmals von Vucetic und Obradovic im Jahre 2000 vorgestellt wurde.
- Erstellen einer Ähnlichkeitsmatrix zur Bestimmung von Beziehungen zwischen Artikeln.
- Aus der Matrix werden die Vorlieben des aktiven Nutzers abgeleitet.
Weitere Formen des Kollaborativen Filterns können auf impliziter Beobachtung der Nutzerverhalten beruhen. Bei diesen Formen des Filterns wird das Verhalten des einzelnen Benutzers mit dem Verhalten aller anderen Benutzer verglichen (Welche Musik haben sie gehört? Welche Produkte haben sie gekauft?). Diese Daten werden genutzt um das zukünftige Verhalten des Nutzers vorhersagen zu können. Dabei ist es nicht sinnvoll, einem Nutzer ein bestimmtes Musikstück anzubieten, wenn er durch sein Verhalten deutlich gemacht hat, dass er es bereits besitzt. Ebenso ist es nicht sinnvoll, einem Nutzer weitere Paris-Reiseführer anzubieten, wenn er bereits einen Reiseführer für diese Stadt besitzt.
Im heutigen Informationszeitalter stellen sich diese und ähnliche Technologien als äußerst hilfreich für die Produktauswahl heraus, gerade wenn bestimmte Produktgruppen (z. B. Musik, Filme, Bücher, Nachrichten, Websites) so groß geworden sind, dass einzelne Personen das gesamte Angebot nicht überblicken können.
Anwendung
BearbeitenIn kommerziellen Systemen
BearbeitenKommerzielle Websites, die kollaboratives Filtern nutzen:
- Amazon
- Barnes & Noble
- Digg.com
- eBay
- Google News[1]
- Hulu
- Internet Movie Database – Filme
- iTunes – Musik
- Last.fm – Musik
- LibraryThing – Bücher
- Musicmatch
- Netflix
- Spotify – Spotify setzt das kollaborative Filtern in seinem Music-Streaming-Dienst für den Service "Empfehlungen" ein.[2]
- StumbleUpon – Websites
- TiVo
- Yelp
In nicht kommerziellen Systemen
Bearbeiten- Rate Your Music – Musik
Literatur
Bearbeiten- Andreas Meier, Henrik Stormer: eBusiness & eCommerce: Management der digitalen Wertschöpfungskette. Springer, Berlin 2009, ISBN 978-3-540-85016-8.
- Robert Buchberger: Wenn es persönlich wird ... - Webpersonalisierung. ( vom 5. Februar 2009 im Internet Archive) auf: contentmanager.de, 6/2001, abgerufen am 14. April 2010
- David Goldberg, David Nichols, Brain M. Oki, Douglas Terry: Using collaborative filtering to weave an information tapestry. In: Communications of the ACM. 35 (12), 1992, S. 61–70.
- Torben Brodt: Collaborative Filtering: für automatische Empfehlungen. VDM Verlag, Saarbrücken 2010, ISBN 978-3-639-25509-6.
Quellen
Bearbeiten- ↑ Abhinandan S. Das, Mayur Datar, Ashutosh Garg, Shyam Rajaram: Google news personalization: scalable online collaborative filtering. In: WWW '07 Proceedings of the 16th international conference on World Wide Web. ACM, New York 2007, ISBN 978-1-59593-654-7. doi:10.1145/1242572.1242610 online
- ↑ Image aus Slideshare "BigDataEurope" Präsentation "How Apache Drives Music Recommendations At Spotify". 29. September 2015, abgerufen am 11. Januar 2016 (englisch).
{kind=link}